서론
STM32에서 ADC를 사용할 때 가장 단순한 방법은 일정 시점에 여러 번 샘플을 읽어 평균을 구하는 방식입니다. 그러나 실제 장비에서는 여러 상태 머신이 동시에 동작하고 있기 때문에, 특정 시점에 ADC를 집중적으로 수행하면 CPU 부하가 증가하고 시스템 전체의 실시간성에 영향을 줄 수 있습니다.
본 글에서는 ADC 샘플링을 시간적으로 분산시키는 Time-Distributed Sampling 구조를 적용하여, 시스템 부하를 줄이면서 안정적인 측정값을 얻는 방법에 대해 설명드리고자 합니다.
본론
기존 방식의 문제점
일반적으로 많이 사용되는 방식은 다음과 같습니다.
for(int i = 0; i < 10; i++)
{
sum += ADC_Read();
}
avg = sum / 10;
이 방식은 구현이 간단하다는 장점이 있지만, 다음과 같은 문제를 가지고 있습니다.
- ADC가 특정 시점에 집중적으로 수행됩니다.
- CPU를 일정 시간 점유하는 blocking 구조가 됩니다.
- 다른 상태 머신의 실행에 영향을 줄 수 있습니다.
- 시스템 응답성이 저하될 가능성이 있습니다.
즉, 단순한 구조이지만 실제 장비에서는 부담이 될 수 있습니다.
분산 샘플링(Time-Distributed Sampling)
이러한 문제를 해결하기 위해 ADC 샘플링을 시간에 분산시키는 구조를 적용할 수 있습니다.
핵심 개념은 다음과 같습니다.
- ADC를 한 번에 여러 번 읽지 않습니다.
- 일정 주기(예: 10ms)로 나누어 샘플링합니다.
- 일정 시간(예: 100ms)이 지나면 평균을 계산합니다.
이 방식은 CPU 부하를 분산시키면서도 평균값을 안정적으로 구할 수 있는 구조입니다.
구조설명
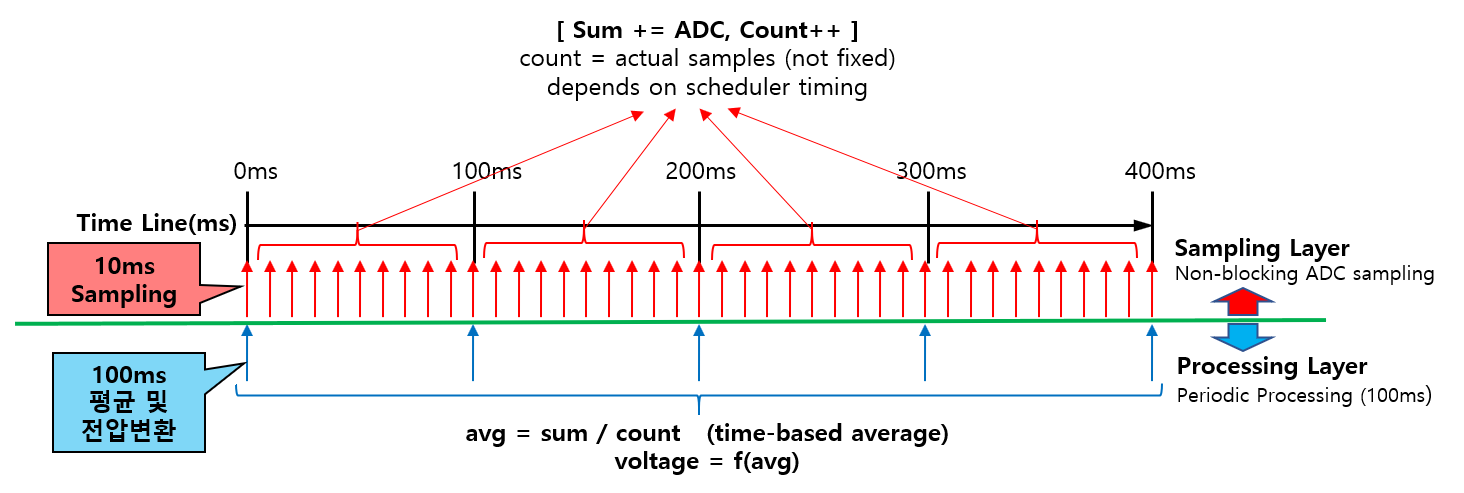
해당 구조는 크게 세 가지 레이어로 구성됩니다.
Sampling Layer(10ms)
- 10ms 주기로 ADC를 1회 수행합니다.
- Non-blocking 방식으로 동작합니다.
- 시스템 전체에 부담을 주지 않습니다.
- sum += ADC_Read();
count++;
Accumulation(누적단계)
일정 시간 동안 샘플이 지속적으로 누적됩니다.
이때 중요한 점은 다음과 같습니다.
count는 고정된 값이 아니라 실제 샘플 개수입니다.
즉, 스케줄러 타이밍에 따라 샘플 개수는 달라질 수 있으며 실제 누적된 샘플 개수를 기준으로 평균을 계산하는 것이 중요합니다.
Processing Layer(100ms)
100ms 주기로 평균 계산 및 전압 변환을 수행합니다.
avg = sum / count;
voltage = f(avg);
이 방식은 단순한 평균이 아니라, 시간 기반 평균(time-based average) 이라는 점이 중요합니다.
핵심 설계 개념
분산 샘플링 구조는 ADC를 단순히 “읽는 방법”을 넘어서, 시스템 전체의 동작 방식과 조화를 이루도록 설계된 하나의 접근 방식이라고 볼 수 있습니다. 핵심은 샘플링과 처리를 명확히 분리하는 데 있습니다. 즉, ADC를 읽는 작업은 짧은 주기로 지속적으로 수행하고, 그 결과를 해석하는 처리는 보다 긴 주기로 수행함으로써 두 작업이 서로 간섭하지 않도록 만드는 것입니다. 이러한 분리는 단순한 구조상의 구분을 넘어서, 시스템의 실시간성과 안정성을 동시에 확보하기 위한 중요한 설계 개념입니다.
샘플링은 10ms와 같이 비교적 짧은 주기로 반복되며, 각 시점에서 한 번씩만 수행됩니다. 이 과정은 매우 짧은 시간 안에 끝나기 때문에 CPU를 점유하지 않고 자연스럽게 다른 작업들과 공존할 수 있습니다. 반면, 평균 계산이나 전압 변환과 같은 처리는 100ms와 같은 주기로 묶어서 수행되며, 그 사이에 누적된 데이터를 기반으로 결과를 산출합니다. 이때 평균은 고정된 개수의 샘플을 기준으로 계산되는 것이 아니라, 실제로 누적된 샘플 개수에 따라 계산됩니다. 따라서 시스템의 타이밍이 약간 변하더라도 안정적으로 동작할 수 있는 구조가 됩니다.
이와 같은 방식은 결과적으로 샘플링을 시간에 분산시키는 효과를 가지며, CPU 부하를 특정 시점에 집중시키지 않고 전체 시간에 걸쳐 고르게 나누어 주는 역할을 합니다. 동시에 평균 계산을 통해 노이즈를 줄이고 보다 안정적인 값을 얻을 수 있기 때문에, 성능과 안정성 사이의 균형을 자연스럽게 맞출 수 있습니다. 무엇보다 중요한 점은, 이러한 구조가 이후 DMA 기반 처리나 보다 복잡한 필터링 기법으로 확장될 때에도 그대로 이어질 수 있는 기반이 된다는 점입니다.
이 설계 방식은 특히 여러 상태 머신이 동시에 동작하는 시스템에서 큰 장점을 가집니다. 예를 들어 모터 제어, 통신 처리, 센서 읽기 등이 동시에 이루어지는 환경에서는 특정 작업이 CPU를 장시간 점유하는 것이 전체 시스템의 동작에 영향을 줄 수 있습니다. 이러한 경우 샘플링을 짧은 주기로 나누어 수행하면 다른 작업과의 충돌을 최소화할 수 있습니다. 또한 온도 센서나 전압 측정과 같이 신호의 변화가 비교적 느린 경우에는, 이러한 분산 샘플링과 주기적 평균 처리 구조가 매우 잘 맞습니다. 노이즈가 많은 환경에서도 일정 시간 동안의 데이터를 평균화함으로써 보다 안정적인 측정값을 얻을 수 있습니다.
결국 이 구조는 “빠르게 자주 측정하고, 느리게 해석한다”는 원칙으로 요약할 수 있습니다. 샘플링은 시스템의 흐름을 방해하지 않는 범위 내에서 지속적으로 수행되고, 처리는 필요한 시점에만 이루어집니다. 이러한 분리는 임베디드 시스템 설계에서 매우 중요한 패턴이며, 단순한 구현을 넘어서 전체 시스템의 품질을 좌우하는 요소가 될 수 있습니다.
결론
ADC 샘플링을 한 시점에 집중시키는 대신 시간적으로 분산시키면, 시스템의 실시간성을 유지하면서도 안정적인 측정값을 얻을 수 있습니다.
특히 Sampling과 Processing을 분리하는 구조는 임베디드 시스템 설계에서 매우 중요한 패턴이며, 향후 DMA 기반 구조로 확장할 때도 자연스럽게 연결될 수 있습니다.
PT100 Temperature Measurement Series
PT100 온도 측정을 위한 아날로그 프론트엔드 설계부터 STM32 ADC Polling, Time-Distributed Sampling, ADC DMA 구현, 3선식 PT100 정전류 구동까지 단계별 실험 및 설계 과정을 정리한 시리즈입니다.
1편: PT100 온도 측정을 위한 AFE(Analog Front End) 설계
PT100 온도 측정을 위한 AFE(Analog Front End) 설계
2편: STM32F103 ADC로 PT100 신호 읽기 (Polling 방식 실험)
STM32F103 ADC로 PT100 신호 읽기(폴링 방식 실험)
3편: STM32 ADC 분산 샘플링(Time-Distributed Sampling) 설계 방법
4편: STM32 ADC DMA를 이용한 PT100 온도 측정 구현
STM32 ADC DMA를 이용한 PT100 온도 측정 구현
5편: 3선식 PT100 정전류 구동 AFE 설계(TLV9062 + INA826)
3선식 PT100 정전류 구동 AFE 설계(TLV9062 + INA826)

“STM32 ADC 분산 샘플링(Time-Distributed Sampling) 설계 방법”에 대한 4개의 생각